This table presents the concerns which initiated the project together with the
subsequent example observations
and discoveries found during load profiling and analysis.
| Concern | Possible
Discovery
| Description / Analysis | Recommendation |
|---|
| VII. Extent and Efficiency of Testing Effort (Testability)
| In HTML, no differentiation of rows for counting among different tables.
| In order to obtain a count of items in different tables on the same page,
a unique identifier is needed for each type of row.
|
Add a unique CSS class= attribute to each type of row.
This is usually a design requirement.
|
| I. User Productivity
| File returned to client is more than 500,000 bytes.
| This guarantees long response times and potential timeouts.
| Pre-cache files in smaller pages hidden in sign-up pages or download in background.
|
| Use of UTF-8 ContentType for English-only pages.
| Additional time is required to process vs. ISO-8559-1.
| Program specification only for pages which need it.
|
| No indication that system is working during long processes.
| Users are likely to abandon the session, click refresh, or other actions which cause even more load.
| Show a "searching... please wait" screen for responses known to be over 5 seconds.
|
| when server is overloaded, users see no screen or technical default text.
| Cryptic HTTP "500" error is shown when servers are too busy to respond.
| Show a "Busy ... Please Try Again Later" screen to users who are not allowed to login due to server overload.
|
| The first user of the day experiences long response times.
| Servers wait until users request specific transactions before loading them into memory,
a task which may take several minutes.
| When server services start, automatically load programs into memory by configuration settings or invoking fake users.
|
| Users must make the same filtering selections repeatedly.
| Values to filter data specified by each user are not presented again.
Retrieving data that users discard consumes CPU, memory, network, and other resources.
| Filter out data that users usually don't want.
|
| III. Stress on the common database machine
| Server error after 5 minutes.
| JVM diagnostics graphs showed that memory peaks at 250mb. This is the default value.
| Specify -xmx:2000m among JVM startup parameters.
|
| Server error after 15 minutes.
| Parallel graphs of diagnostics showed that the number of Weblogic sessions flattened out at 250. This is the default number.
Since the timeout is 20 minutes, runs require 35 sessions per user per minute.
| Specify the maximum number of sesssions in the config.xml file.
|
| High disk utilization.
| 10GB of disk space is consumed per hour of peak load.
| In productive system simulations, use "Error" level logging.
|
| Maximum app loads did not overload the DB server.
| The major concern of this project was the impact on the Oracle machine. Runs at the largest application volume increased CPU utilization by no more than 25% with AP transactions, which had the most impact on the server.
| Identify and test for the total possible load on the DB running all apps at possible peak loads.
|
| II. Operational Efficiency: Stability of the configuration (Readiness of the app. for production)
| An image file was not found on page "Xyz".
|
Microsoft browsers automatically request the favicon.ico file,
which generates an error if it's not on the website's root folder.
| Workaround: Script loadtest to ignore the "404" error.
Root cause: Provide the file with the name expected by the app code or change the code.
|
II. Efficient
Resource
Utilization
| Spikes in performance.
| Longevity tests confirm that spikes in response time were eliminated after
changing the JVM run-time setting in the server start-up to specify a) more memory to permgen, b) availability of multiple processors,
c) incremental garbage collection.
in the server start-up to specify a) more memory to permgen, b) availability of multiple processors,
c) incremental garbage collection.
|
| Server shutdown during overnight runs.
| The server shutdown near the end of Longevity tests because it ran out of file handles.
When the OS was setup with the maximum rather than the default number of file handles, the app completed longevity tests.
An additional temporary workaround is to recycle each process once a day.
|
Workaround: Configure the OS with more file handles/descriptors.
Root cause: Change app code to explicitly close files.
|

 Load, Stress, Performance Test Terms, Deliverables, Profiles and Reports
Load, Stress, Performance Test Terms, Deliverables, Profiles and Reports




 These are good candidates for "Six Sigma" improvement projects.
These are good candidates for "Six Sigma" improvement projects.
 For $49, buy and download
For $49, buy and download  provides a link to a captured screen image of the app.
provides a link to a captured screen image of the app.

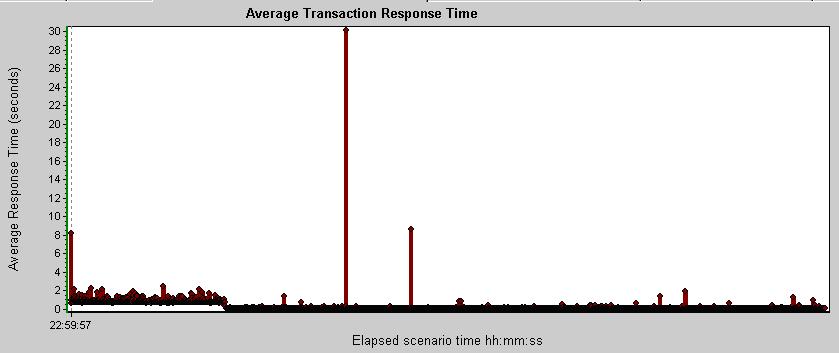


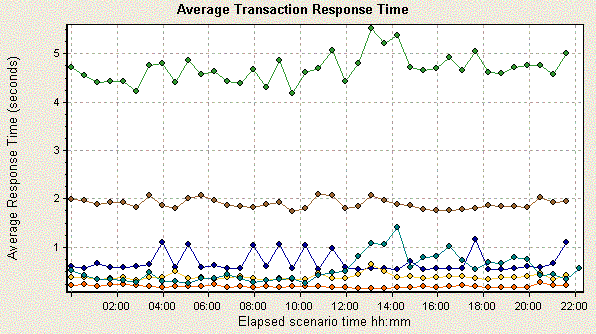


 From a 1MB Powerpoint 2003 slideshow containing voice narration:
From a 1MB Powerpoint 2003 slideshow containing voice narration: