InfoProviders are objects or views relevant to reporting, which
queries in SAP BW can be created or executed.
There are two types of InfoProviders:
- objects that contain physical data, called data targets:
- InfoCubes —
self-contained datasets for a business-oriented area,
with a set of relational tables created with a star schema.
Such datasets can be evaluated using BEx query.
- DSO/ODS (DataStore Object/Operational Data Store) objects
which store master data and flow data in flat structures
containing key fields and data fields referenced by index tables to primary objects.
DataStore objects relevancy indicators are the basis for selecting data in the Source Data Layer.
Such objects are used in the Tool BI part of Bank Analyzer.
- InfoObjects (characteristics with attributes, texts, or hierarchies).
- objects that display no physical data storage:
- ISets (InfoSets) a SAP Query element which determine the
tables (or fields within a table) to which a query can refer.
InfoSets are usually based on table joins (logical databases).
- RemoteCubes ,
- SAP RemoteCubes , and
- MP (MultiProviders) provide views
which combine data from all types of InfoProviders
(collated using a union operation).
MultiProviders are used for logical partitioning.
Global queries on independent basis InfoProviders with cumulative key figures
are by default parallel
and united at a defined synchronization point.
However, global queries though a MultiProvider can be manually switched to serial processing
(using transaction RSRT, per SAPnote 449477).
- VP (VirtualProviders) provide a path for read-only
direct access to data stored in the BI system or in other SAP systems or non-SAP systems.
Each InfoProvider is assigned to an IA (InfoArea) for
grouping meta-objects in the BI system,
as displayed in the Data Warehousing Workbench.
In addition to their properties as an InfoProviders,
InfoObjects can also be assigned to different InfoAreas.
Star Schema: a large fact table in the center, with several dimension tables surrounding it.)
An extended star schema includes Navigational attributes.
These require additional table joins at runtime
(versus dimension characteristics which do not).
Aggregates with navigational attributes require change runs to be scheduled
every time this master data is loaded.
AG (Aggregate) store the dataset of an InfoCube redundantly and persistently in a summarized form in the database.
When building an aggregate from the characteristics and
navigation attributes of an InfoCube,
you can group the data according to different aggregation levels.
Remaining characteristics that are not used in the aggregate are summarized.
New data is loaded into an aggregate using logical data packages (requests).
You differentiate between filling and rolling up with regard to loading data.
Aggregates enable you to access InfoCube data quickly for reporting.
Thus, aggregates help to improve performance.
ISP (InfoSpoke) object for the export of data within the open hub service.
Defined in the InfoSpoke are the following:
- from which open hub data source the data is extracted,
- in which extraction mode the data is delivered, and
- into which open hub destination the data is delivered.
An IP (InfoPackage) describes which data in a DataSource should be requested from a source system.
The data can be precisely selected using selection parameters.
An InfoPackage can request the following types of data:
Transaction data, Attributes for master data, Hierarchies for master data,
Master data texts.
APD - Analysis Process Designer is a tool used to model an analysis process.
It provides a graphical interface to model analysis processes.
An analysis process is built using nodes and data flow arrows.
The nodes stand for data sources, transformations and data targets.
The dataflow arrows model the sequence in which the data is read and transformed.
A PC (Process Chain)is a sequence of processes that are scheduled in the background to wait for a particular event.
Some of these processes trigger an additional event,
which in turn can start other processes.

 SAP Business Intelligence
SAP Business Intelligence
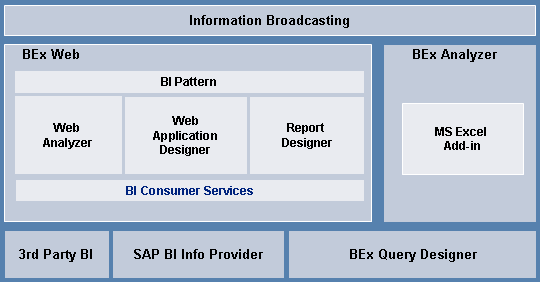
 Excel-based BEx Analyzer uses many more round-trips and transferred data to the server than
web frontend.
Excel-based BEx Analyzer uses many more round-trips and transferred data to the server than
web frontend.
